The Economics of Cloud
Enterprises have been collecting large volumes of sales and customer behavior data through POS and ecommerce systems,and they are eager to leverage the power of predictive analysis of the data to improve the fundamentals of their business.
Predictive analytics take advantage of the data, building models that help support business decisions.
However, models need the flexibility to change as business requirements change, and the supporting IT
infrastructure needs to change as well. Given the complexity of inter-connected models, the run time to calculate
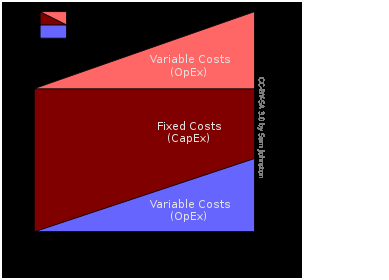
optimal price for an item can easily jump from 1 min. to 5 mins. Dedicated IT infrastructure, using capital expenditure,
simply cannot scale up with demand.
Cloud computing is the only way out of this conundrum. You start with today’s need,
which is a small set of resources, funded by operational expenses. As the models expand in
complexity, you keep adding incremental resources. You never have to plan for a heavy peak usage,
where the large investment sits idle for the most part, and you never have to worry about running out of capacity in the middle of a vital model run.
Analytics on the Cloud
Forecast Horizon has been taking advantage of Amazon Web Services (AWS) to build a high-performing analytical stack,which has ZERO fixed cost, and scales on demand.
Storage
Most enterprises are paying big sums to commercial vendors for data storage, and these are dedicated to running production applications.The cost of replicating a large data set for analysis purposes, using the same commercial tools is prohibitively expensive.
Replicating the same data, on a system like Amazon’s S3 storage, purely for analysis, is very cheap. Since analytical techniques are often run in a batch-mode,
the data remains in passive storage for most of the time, and gets attached to a processing engine
(either open-source RDBMS like MySQL or map-reduce like Hadoop) on an as-needed basis.
AWS is designed to separate storage cost (paid by GB/month) and processing cost(paid by CPU/hour),
so you do not pay for CPU costs when data is in passive storage.
Software
Forecast Horizon uses open-source packages such as R for statistical modeling, andCOIN-OR for complex, non-linear, optimization. While these packages can run outside
the cloud, the fact that they are open-source means that they can be replicated across a large number of machines,
without getting bogged down by licensing issues. At a Fortune 500 customer, Forecast Horizon was running over 1
000 CPU’s in parallel, and a per-CPU licensing would have rendered the exercise prohibitively expensive.
Compute Power
This is where AWS really shines for retail analytics. Take for instance the problem of price-optimization,where running a moderately complex algorithm for a product can easily take one minute. A mid-sized retailer
carries 10K products, which means that a price-optimization batch run takes 10,000 minutes on a single CPU, in a serial mode.
This is clearly not an acceptable solution from a business stand-point, because by the time the model has produced an answer,
it is already obsolete due to the changing business condition (sales, inventory, demand, etc.)
Using AWS, Forecast Horizon can split the same problem across 100 servers running in parallel,
to reduce the problem to 100 minutes, or across 1000 servers running in parallel, to reduce the problem to 10 minutes.
Forecast Horizon does not have to own any of the servers, and only pays for the CPU hours consumed. Forecast Horizon
also does not have to worry about the underlying architecture that makes it possible to spin up 10, 100 or 1000 servers with a single API call.
Summary
Despite a lot of hype, misconceptions, and derisions, the AWS cloud is a ground-breaking tool forcomplex analysis of large volumes of data. S3 offers cheap storage, EC2 instances offers CPU on-demand,
scaling easily from 1 to 10 to 1000. While it may not make sense for enterprises to overnight shift their
payroll and account receivables to the cloud, but it offers them the opportunity to ask questions that they
did not imagine could be answered.

 Fusion Charts
Fusion Charts
